Since I started playing ChatGPT in December last year, I have gone through three stages of ecstasy, careful thinking and fear, and calmly facing it now. For most of us who are about to retire at the age of 65, there are many uncertainties in the road ahead. For a while, I even began to consider whether to stop my retirement.
According to Gartner research:
— By 2025, 30% of outbound marketing messages from large organizations will be synthetically generated, up from less than 2% in 2022.
–By 2025, 30% of new drugs and new materials will be systematically discovered by generative AI technology.
— By 2030, 90% of movies will be generated by AI (from text to video), up from 0% in 2022.
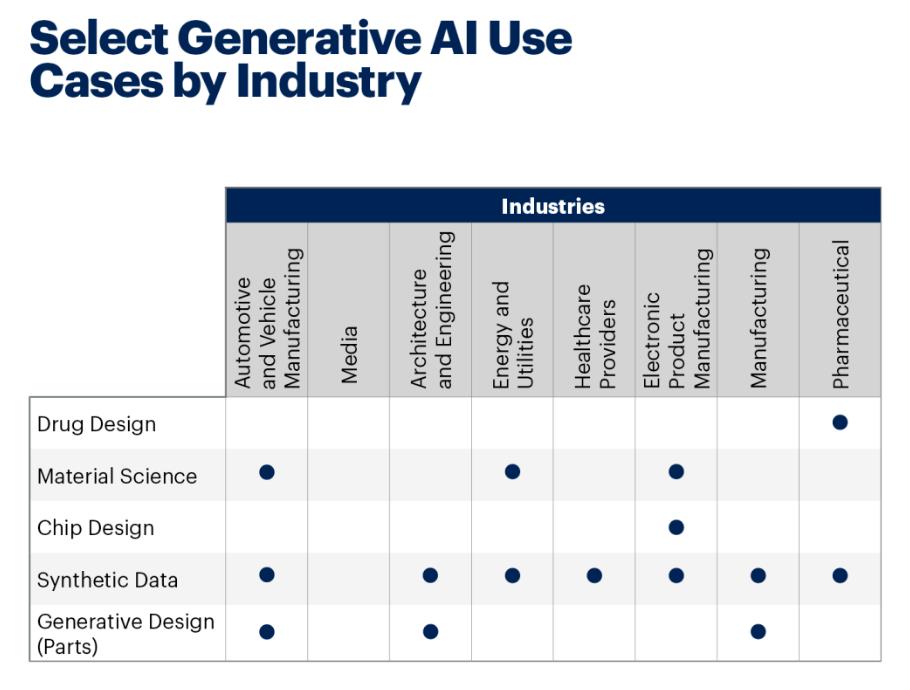
However, if you discover the significant difference between artificial intelligence and human beings, you will be able to face up to the value of human beings—only human beings can provide Opinions and Insights, and only human beings will pursue small probability events. This is the greatest driving force for innovation.
After all, at least for most of the time, what we are doing is human said, and what AI is doing is copy it.
We have three options for ChatGPT: ignore it, block it, and embrace it. In any case, we must first understand the source of information on ChatGPT.
What is the information source of ChatGPT?
ChatGPT is based on GPT-3.5, also known as InstructGPT. It uses human feedback reinforcement learning technique RLHF. The dataset used for training is:
- Common Crawl, that is, common crawl (filtered)
- WebText2
- A category of books
- Second-class books
- Wikipedia
The first two of the above five datasets are crawling of the Internet. WebText2 is a private dataset of OpenAI that crawls Reddit with more than three likes. The reason, of course, is that the content is more credible and higher quality.
What to do if you don’t want ChatGPT to crawl?
So, obviously if you don’t want your content to be used by ChatGPT, the best way is not to be crawled by Common Crawl. The direct way to control web pages from being crawled by Common Crawl robots is to add guidelines to prohibit crawling in robots.txt.
This SEO should be familiar:
User-agent: CCBot
Disallow: /
It should be noted that, like most crawlers, sometimes its User Agent will masquerade as other robots or normal users. So there is no such thing as a safe approach. Unless you even ban the search engines.
What to do if you want ChatGPT to get more adoption of your content?
Do a good job of website SEO
As we said above, artificial intelligence still needs to crawl your website through robots to obtain your content. Therefore, to do a good job in SEO is to do a good job in the crawlability of the website, which can make the content of your website be obtained by artificial intelligence.
Only when the robot acquires the content and crawls the text on the Internet can it establish the basis for understanding the content of your article.
There are many ways to improve the crawlability of the website, including the robots.txt we introduced before, and the need to avoid using JavaScript to reflect our content. Because robots use JavaScript to render our site’s content, more resources will be required.
2. Produce content for ChatGPT
Usually, you don’t need to worry about this, you just prepare content for real humans. But in order for artificial intelligence to understand your content better, you need to write more organized, so that AI can see the logic of your content.
So it is good practice to add a summary to your article. In each paragraph and chapter, there needs to be obvious hierarchical segmentation, and the importance of learning Chinese well is reflected here.
You can use self-question and self-answer methods to reflect more valuable content, provided that you know what questions Internet users will ask. But don’t use the text that ChatGPT gives you, just use it directly.
3. Add structured data to help AI understand your content
Although we don’t know whether ChatGPT will use structured data to understand the content of our web pages in the future, I believes that this will definitely be a trend in the future. Structured data can convert text into entities, helping artificial intelligence to better understand the true meaning of language in our web pages.
4. Add links in trusted sites and manage well
We introduced earlier that ChatGPT uses a lot of content including the Reddit community as its training corpus, and also obtained many credible links from these websites to enrich its content.
Try standing on the shoulders of giants.
In conclusion:
It is only in the early days of generative AI, but from the perspective of natural language processing NLP, we have quietly developed for many years and finally ushered in the first small peak. With this small peak, we can see many applications that can be landed and commercialized.
Above we introduced how to use the features we have about ChatGPT to do a good job in content marketing. No matter what choices you make, the explosion of artificial intelligence will upend our old internet order. All we can do is to understand these changes earlier and think about how to evolve our existing marketing infrastructure.